
Adam Spannbauer
Data Scientist/Instructor・Mostly write Python & R for pay・Mostly write p5js for fun・Check me out @thespanningset on Instagram
Keras FRCNN Object Detector for Fox in SSBM
Published Dec 28, 2017
In this post I’ll be sharing a computer vision model that was trained to detect the character Fox in the game Super Smash Bros Melee for the Nintendo Gamecube.
Here’s a sneak peak at the output if you aren’t too intereseted in reading more about the process.
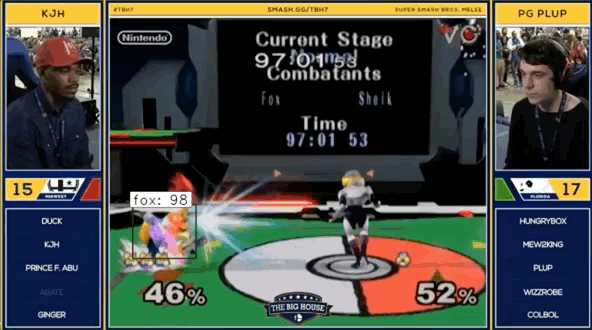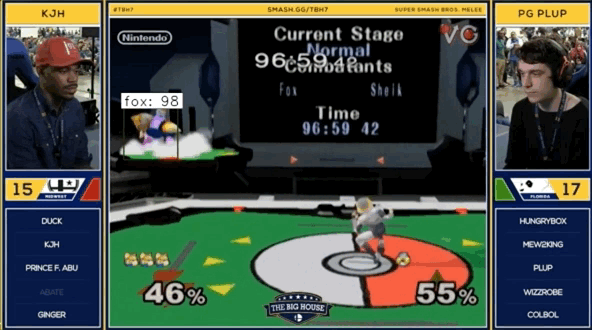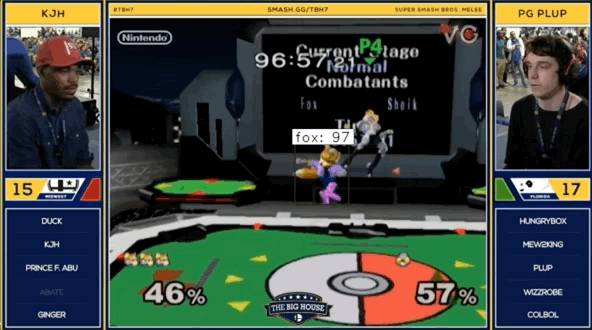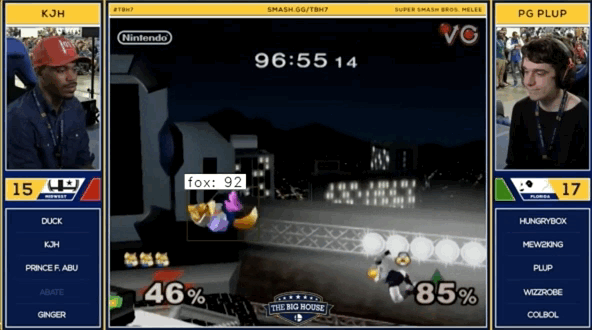
The Process
Thanks to there already being a keras-frcnn framework coded up, the steps to making this fox model were reduced to (1) gathering/tagging training data, (2) training the model, & (3) testing the model.
This will be a relatively high level overview. If you have any specific questions about the process please leave a comment, and I’ll do my best to help answer it.
1. Gathering & tagging training data
The data used was from the prominent Super Smash Bros streamer VGBootCamp. Training data was gathered from the tournament Smash Conference. Testing data was gathered from The Big House 7.
Bounding boxes were annotated in 348 frames of gameplay for training. The bounding boxes were drawn using imglab.
2. Training the model
Thanks to the effort put in by the keras-frcnn authors and Adrian Rosebrock of PyImageSearch the training step was relatively simple. I used the PyImageSearch pre-configured Amazon AMI as the location for model training. Once the server was spun up I followed the instructions listed in the readme of the keras-frcnn repo. Since I only had 348 training images I supplemented the training by using horizontal flips, vertical flips, and 90 degree rotations. After a couple days, I stopped the training process to try out the model.
3. Testing the model
Again thanks to standing on the shoulders of giants, testing the model was a relatively simple task. To test I followed the instructions in the readme of the keras-frcnn repo, and I was pleasantly surprised by the results. The model was correctly finding and annotating Fox in a majority of the test images! However, I did not tag the testing images, so there is no quantitative metric on the model’s accuracy.
The .gif at the top of this post shows a combination of man.
Sources
- keras-frcnn github repo
- Fast R-CNN white paper
- PyImageSearch Deep Learning for CV AMI
- imglab
- VGBootCamp (twitch & youtube)
Update
I forgot to link to the github repo for this project. The repo has all the code, links to training data, & usage information.