
Adam Spannbauer
Data Scientist/Instructor・Mostly write Python & R for pay・Mostly write p5js for fun・Check me out @thespanningset on Instagram
Summarizing Web Articles with R using lexRankr
Published Dec 17, 2017
In this post we’ll be recreating the output of a popular summarization bot using the R package lexRankr.
If you browse reddit you may have come across /u/autotldr, a popular bot that performs article summarization. The bot can be seen in comment sections posting summaries such as the one seen below. A lot of redditors agree the bot does a pretty good job of summarizing (as seen by the 10,048 points the comment earned).
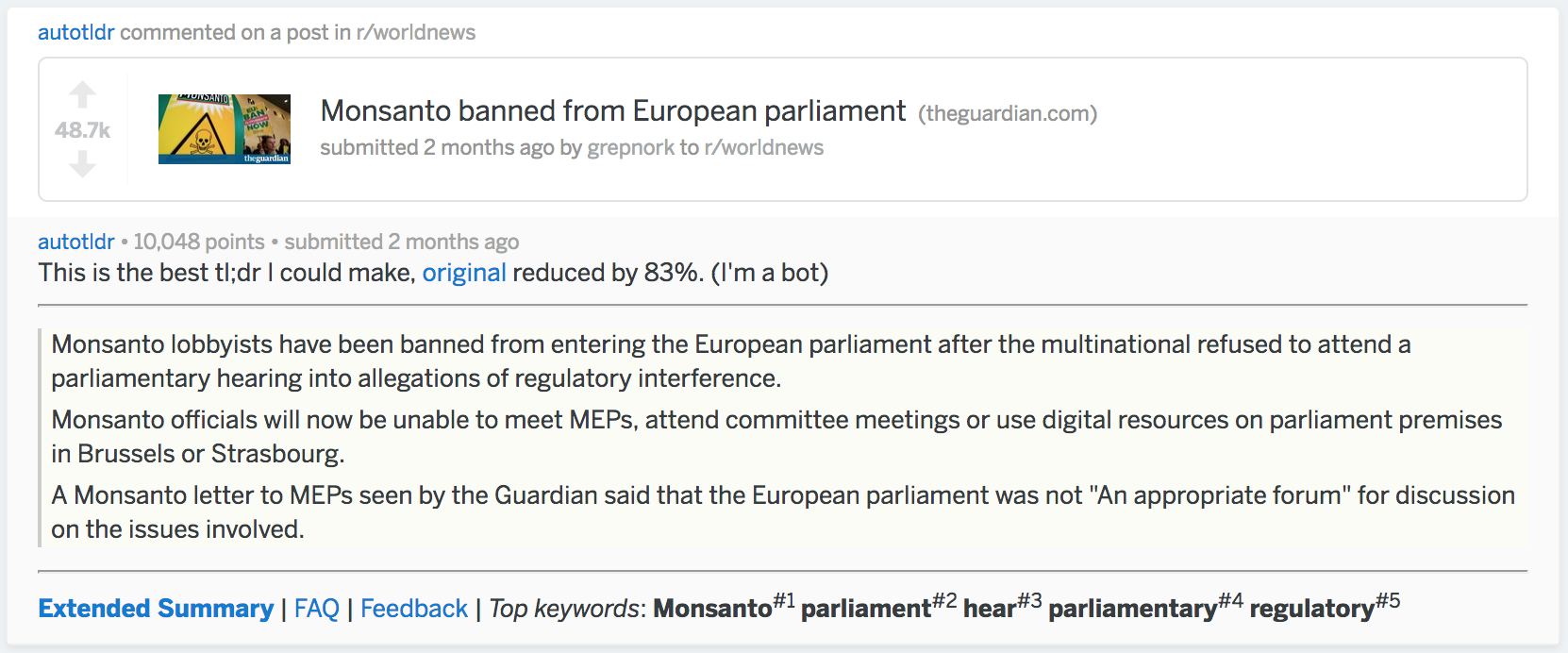
So let’s begin to recreate the output. We’ll just work on replicating the sentences portion of the summary; we won’t go into the extended summary or the keywords. To be able to compare performance with the bot we’ll use the Monsanto banned from European parliament article from the above screenshot.
The 2 main steps of our summarization task are (1) scrape the article’s text & (2) perform the summarization. For step (1) we’ll be using the R packages xml2 & rvest. For step (2) we’ll use the lexRankr package.
Let’s start step (1) of scraping the text to be summarized. For our proof of concept we’ll use a very specific css selector to scrape the text; this strategy will need to be modified if we want to apply our scraper to more articles. In the chunk below we complete step (1) in 3 lines of code (exluding library statements).
#load needed packages
library(xml2)
library(rvest)
library(lexRankr)
#url to scrape
monsanto_url = "https://www.theguardian.com/environment/2017/sep/28/monsanto-banned-from-european-parliament"
#read page html
page = xml2::read_html(monsanto_url)
#extract text from page html using selector
page_text = rvest::html_text(rvest::html_nodes(page, ".js-article__body p"))
Now that we have our text it’s time to complete the task of performing the summarization. To do the summarization we’ll apply the LexRank algorithm. The LexRank algorithm is essentially Google’s PageRank, but instead of using pages as our input we will use sentences. The goal of LexRank is to find the most representative sentences of a corpus. The lexRank() function from lexRankr has an implementation of LexRank that can take our page_text object as input for summarization.
#perform lexrank for top 3 sentences
top_3 = lexRankr::lexRank(page_text,
#only 1 article; repeat same docid for all of input vector
docId = rep(1, length(page_text)),
#return 3 sentences to mimick /u/autotldr's output
n = 3,
continuous = TRUE)
#reorder the top 3 sentences to be in order of appearance in article
order_of_appearance = order(as.integer(gsub("_","",top_3$sentenceId)))
#extract sentences in order of appearance
ordered_top_3 = top_3[order_of_appearance, "sentence"]
Let’s take a look at our output stored in ordered_top_3:
"Monsanto lobbyists have been banned from entering the European parliament after the multinational refused to attend a parliamentary hearing into allegations of regulatory interference.""Monsanto officials will now be unable to meet MEPs, attend committee meetings or use digital resources on parliament premises in Brussels or Strasbourg.""A Monsanto letter to MEPs seen by the Guardian said that the European parliament was not “an appropriate forum” for discussion on the issues involved."
Success! We were able to replicate the exact output of the autotldr bot for this particular article in less than 10 lines of R code!
Note: The bot is still taking on a greater challenge than what was done in this post since we had the advantage of using a hardcoded css selector for just this one article.