
Adam Spannbauer
Data Scientist/Instructor・Mostly write Python & R for pay・Mostly write p5js for fun・Check me out @thespanningset on Instagram
Profanity in Twitch Chat
Published Mar 12, 2017
This post contains references to profane language. All instances of profanity on this page have been censored.
The post is part tutorial with code chunks, if you are uninterested in the data manipulation steps you can jump to Visualizing Profanity in Chat to see the results.
Background
In this post we’ll be analyzing profanity in a Twitch.tv chat. The data was collected during the final day of Smash the Summit Spring 2017. The tournament boasted the largest prize pool in Melee tournament history at $51,448. The full past broadcast of the final day (including a chat replay) can be found at Beyond the Summit’s twitch channel. If you are interested in learning more about the competitive Melee scene you can check out /r/smashbros.
Packages Used in this Post
library(tidyverse)
library(tidytext)
library(stringr)
library(hunspell)
library(fuzzyjoin)
library(plotly)
Data Prep
The twitch chat data was collected using the autolog in the IRC client Irssi. A processed version of the chat log can be found on my github.
In order to detect profanity we’ll be using a list of FCC banned words.
Clean Chat Data
Before we start analyzing the chat messages we’ll need to clean the text. The code chunk below splits chat messages into single words, removes stopwords, and performs word stemming. Laslty, words deemed as ‘problem words’ are removed from the chat as well. Problem words have been manually collected to limit false positives when we try to detect typod curse words. An example of a problem word is ‘duck’ since it’s one character away from a popular curse word.
#tokenize chat messages into single words
chat_tokens <- chat_df %>%
unnest_tokens(token, msg) %>%
#replace na tokens with blank str
mutate(token = if_else(is.na(token),"",token))
#remove stopwords, problem words, and stem
chat_tokens_clean <- chat_tokens %>%
#remove stop words
anti_join(stop_words, by=c("token"="word")) %>%
#stem words
mutate(token_stem = vec_hunspell_stem(token)) %>%
mutate(token_stem = if_else(token_stem %in% problem_words_df$problem_words,
"",
token_stem))
Fuzzy Join FCC and Chat Data
Now that we have a table of words in chat, we’ll detect FCC banned words using a fuzzy join based on string distance. Using this fuzzy join will allow us to catch some typos of our banned word list. If the string distances using Optimal String Alignmentis under 1 then we will set a curse_flag on the chat word.
#join chat tokens to fcc banned tokens when stringdist <= threshold
# stringdist method = "osa"; threshold = 1
chat_tokens_join <- chat_tokens_clean %>%
stringdist_left_join(fcc_wont_let_me_be,
by=c("token_stem"="bad_token"),
max_dist=1) %>%
mutate(curse_flag = if_else(is.na(curse_flag),0,1))
Visualizing Profanity in Chat
FCC Banned Word Frequencies
Next we’ll take a look at which FCC banned words were the most popular overall. The top 2 words account for 4013 of the 4575 (r paste0(round(100*(4013/4575), 0),"%")), so we’re going to collapse the words into 3 groups before we plot. The groups will be f**k, s**t, and all others. Once we have the data summarized into these 3 groups we’ll make a bar chart using plotly.
The plot’s code is not displayed here but can be seen in the appendix.
fcc_word_count <- chat_tokens_join %>%
#filter out non curse words
filter(curse_flag == 1) %>%
#censor tokens.. fcc wont let me be
mutate(bad_token = censor(bad_token, "u|c|h|i","*")) %>%
#summarise and count each banned word
count(bad_token) %>%
#create groups for top 2 curses and catchall group
mutate(group=map_chr(bad_token, function(x) {
if (!(x %in% c("f**k","s**t"))) {
out = "all others"
} else {
out = x
}
out
})) %>%
#convert group to factor for order in plot
mutate(group=factor(group,
levels=c("f**k","s**t",
"all others"))) %>%
#sum count for all others group
group_by(group) %>%
summarise(n=sum(n)) %>%
ungroup()
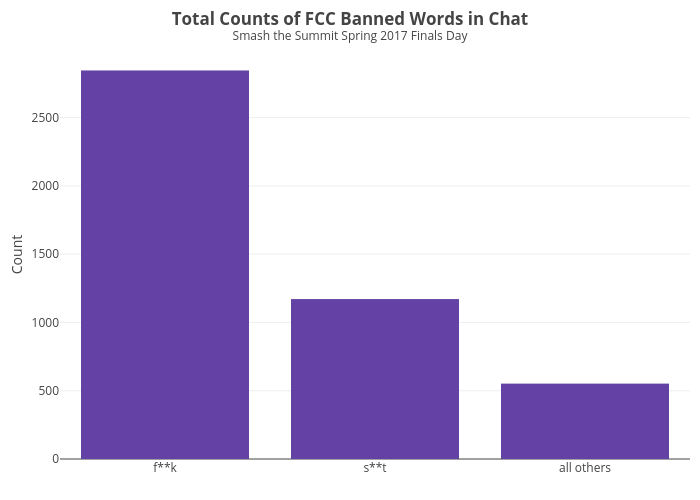
FCC Banned Words Over Time
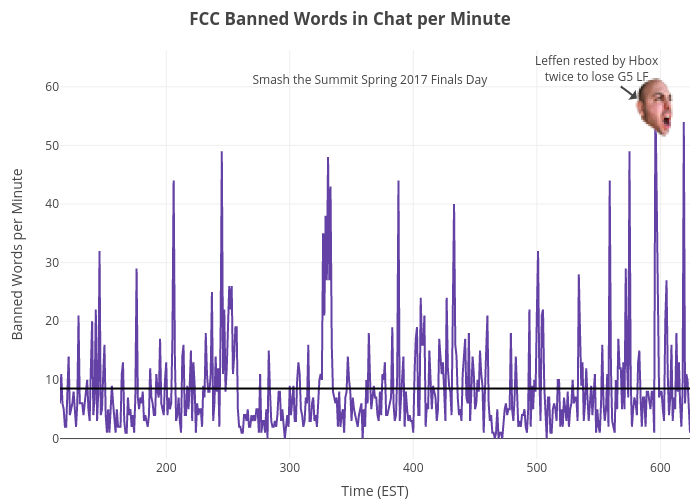
Now we’ll plot a time series of FCC banned words per minute, and annotate the most profane minute. The average banned words per minute is 8 (shown by the black line in the plot) with the max being 58 (annotated with the SwiftRage twitch emote). The max curse words per minute happened when Liquid.Hungrybox made a shocking come back on TSM.Leffen; the most used banned word in this minute was f**k.
The plot’s code is not displayed here but can be seen in the appendix.
fcc_by_min <- chat_tokens_join %>%
#group at minute level (preserve date)
group_by(date, time) %>%
#sum curse counts per minute; store all words in list column
summarise(curse_count = sum(curse_flag),
curse_words = list(bad_token[!is.na(bad_token)])) %>%
ungroup() %>%
#create var of most used curse word per minute
#(words concat with / if tie)
mutate(top_curse = map_chr(curse_words,censored_word_mode)) %>%
#index minutes for use in plots
mutate(minute_i = row_number())
Appendix
Plot Code
FCC Banned Word Counts Bar Plot
plot_ly(fcc_word_count,
x=~group,
y=~n,
type="bar",
marker=list(color='#6441A4')) %>%
layout(title="<b>Total Counts of FCC Banned Words in Chat</b>
<br>
<sup>Beyond the Summit Spring 2017 Finals Day</sup>",
xaxis=list(title=""),
yaxis=list(title="Count"),
margin=list(t=50))
FCC Banned Words per Minute Line Plot
time_labels <- fcc_by_min %>%
filter(str_sub(time, -2) == "00") %>%
select(minute_i, time)
max_row <- fcc_by_min[which.max(fcc_by_min$curse_count),]
plot_ly(data=fcc_by_min %>%
filter(minute_i>113) %>%
filter(!is.na(time)),
x=~minute_i,
y=~curse_count,
type = "scatter",
mode = "lines",
line = list(color = '#6441A4'),
hoverinfo = "text",
text = ~paste0("Count: ", curse_count,
"<br>",
"Top Word: ", top_curse,
"<br>",
"Time: ", time)) %>%
add_trace(x = ~c(min(minute_i):max(minute_i)),
y= ~mean(curse_count),
mode = "lines",
line = list(color = 'black'),
hoverinfo="text",
text = ~paste0("Avg Count: ", floor(mean(curse_count)))) %>%
layout(title="<b>FCC Banned Words in Chat per Minute</b>
<br>
<sup>Beyond the Summit Spring 2017 Finals Day</sup>",
xaxis=list(title="Time (EST)",
tickmode="array",
tickvals=time_labels$minute_i,
ticktext=time_labels$time),
yaxis=list(title="Banned Words per Minute"),
margin=list(t=50),
showlegend = FALSE,
annotations=list(x = max_row$minute_i-15,
y = max_row$curse_count,
text = "Leffen rested by Hbox
<br>
twice to lose G5 LF",
xref = "x",
yref = "y",
showarrow = TRUE,
arrowhead = 1,
ax = -40,
ay = -30),
images=list(list(source =
"https://static-cdn.jtvnw.net/emoticons/v1/34/2.0",
xref = "x",
yref = "y",
x = 580,
y = 61.5,
sizex = 30,
sizey = 10,
sizing = "stretch",
layer = "above")))
Helper Functions
##vectorised hunspell stemmer----------------------------------------------------
my_hunspell_stem <- function(token) {
stem_token <- hunspell::hunspell_stem(token)[[1]]
if (length(stem_token) == 0) return(token) else return(stem_token[1])
}
vec_hunspell_stem <- Vectorize(my_hunspell_stem, "token")
##function to censor bad words in print------------------------------------------
censor <- function(sailor_vocab, censor_regex="a|e|i|o|u", replace="*") {
stringr::str_replace_all(tolower(sailor_vocab),
stringr::regex(censor_regex),
replace)
}
##function extract mode------------------------------------------
censored_word_mode <- function(curse_vec) {
if(length(curse_vec) == 0) return("NA")
curse_vec %>%
table() %>%
.[which(.==max(.))] %>%
names() %>%
censor() %>%
paste(collapse="/")
}